PDFをExcelに変換
あらゆるPDFからテーブル、財務諸表、構造化データを抽出し、手動でのコピー&ペーストなしで、クリーンな数式対応のExcelワークブックに変換します。
プライベートエクイティ、ベンチャーキャピタル、グロースエクイティ、不動産、ヘッジファンドにわたる1,000人以上の財務プロフェッショナルに信頼されています。
重要な業務を行う財務チーム向けに構築
プライベートエクイティ
CIMやデューデリジェンスファイルから、営業指標、アドバック、KPIテーブルをExcelモデルに取り込みます。
ヘッジファンド
提出書類、投資家向けプレゼンテーション、決算資料からデータを抽出し、調査ワークフローを高速化します。
不動産
賃料ロール、オファリングメモランダム、貸し手パッケージを、クリーンで分析可能なスプレッドシートに変換します。
投資銀行
PDFからの財務諸表テーブルを標準化し、比較分析やモデリングのためのワークブック対応タブに変換します。
仕組み
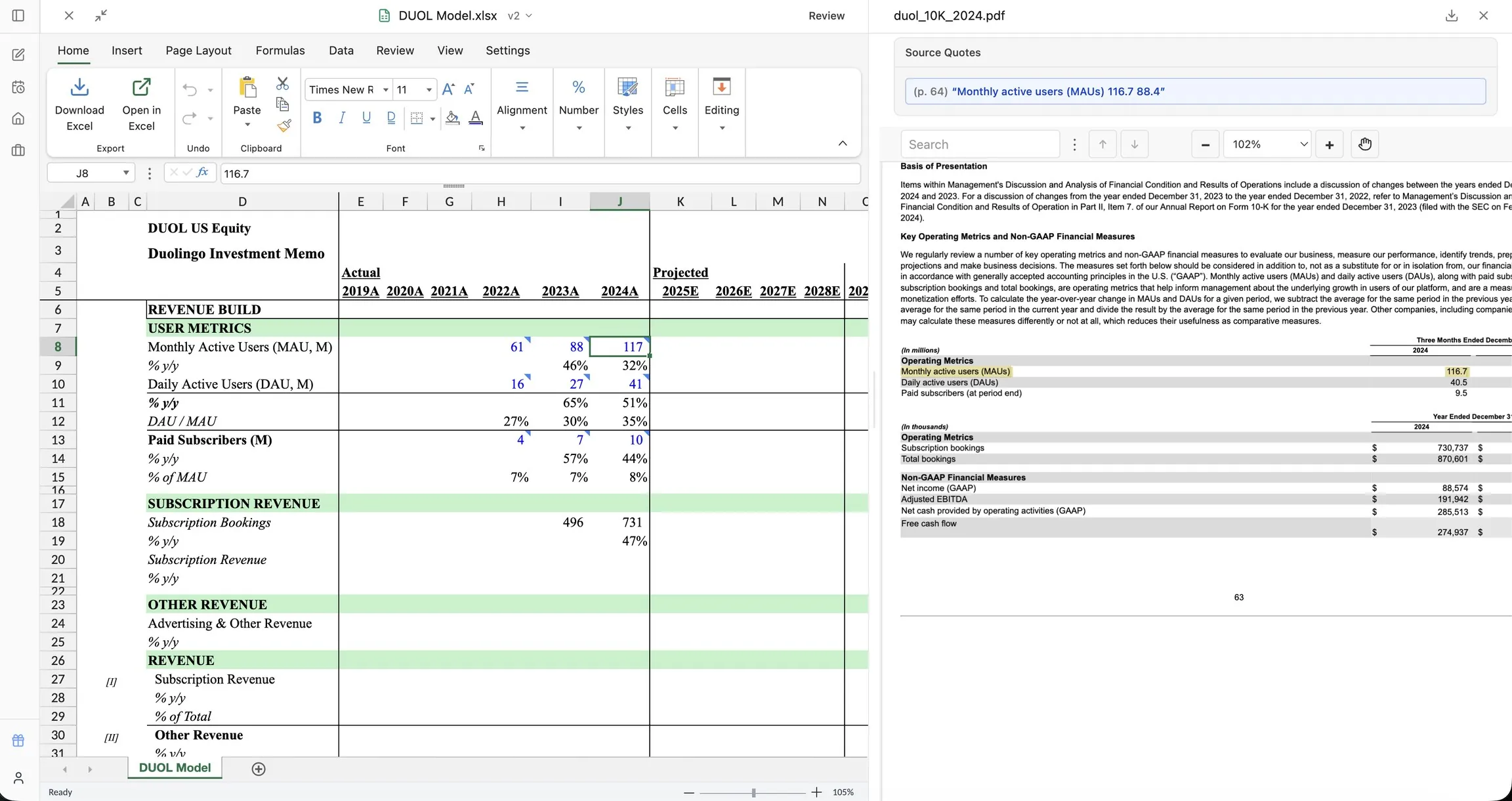
PDFをアップロード
財務諸表、レポート、データテーブルなど、あらゆるPDFをCompoundワークスペースにドラッグ&ドロップします。
必要なデータを依頼
AIアナリストに抽出するデータを正確に指示します。特定のテーブル、範囲、またはドキュメント全体。財務コンテキストを理解します。
クリーンなスプレッドシートを取得
適切なフォーマットと引用ソース付きの構造化Excelワークブックを受け取ります。抽出されたすべての値は元のPDFページまで遡ることができます。
財務PDFの抽出が難しい理由
汎用のPDF-to-Excelツールは、財務プロフェッショナルが日々扱う複雑でリスクの高いドキュメントには対応しきれません。
複雑なテーブルレイアウト
財務諸表はネストされたヘッダー、結合セル、小計、多段階インデントを使用しています。汎用OCRツールはこれを平文に変換してしまい、数値に意味を与える階層構造が失われます。
複数ページにわたるテーブル
CIMや10-K内の1つのテーブルが、繰り返しヘッダーや異なる列幅を伴いながら複数ページにわたることがあります。ほとんどのツールは各ページを独立して処理するため、データが断片化されます。
ドキュメント品質の混在
データルームにはデジタルネイティブのPDFとスキャンしたドキュメントが混在しており、同一ファイル内に両方が含まれることもあります。それぞれ異なる抽出アプローチが必要ですが、ほとんどのツールはどちらか一方にしか対応していません。
文脈依存の数値
「1,250」という数値は、百万単位の売上、従業員数、または平方フィートを意味する可能性があります。財務コンテキストがなければ、抽出ツールはモデル内で値を正しくフォーマット、分類、配置することができません。
Compoundが優れている理由
財務グレードの精度
財務ドキュメント専用に構築されています。Compoundは、汎用ツールでは崩れてしまう損益計算書レイアウト、貸借対照表、複数年テーブルを理解します。
検証可能な引用ソース
抽出されたすべての値は、ソースPDF内の正確なページと場所を引用するため、ワンクリックで任意の数値を検証できます。
バッチ処理
数十のPDFを1つのワークスペースにアップロードし、1つの会話ですべてのデータを抽出できます。ファイルごとの面倒な作業は不要です。
サポートされる入力と出力品質
一般的なPDF入力
- スキャンされたPDFとネイティブPDF
- 10-K、10-Q、年次報告書、提出書類
- 財務諸表および脚注テーブル
- データルームファイルおよび投資家向け資料
Excelで得られるもの
- 構造化されたタブとクリーンなヘッダー
- 正しい数値フォーマットと型付きセル
- 数式対応のワークブックレイアウト
- ソースページへの引用
財務ワークフローでは、違いはスピードだけではありません。信頼性と監査可能性です。
手動コピー&ペースト
- テーブル構造の保持
脆弱で時間がかかる
- 財務コンテキストの理解
アナリストの努力に依存
- 引用のトレーサビリティ
手動メモが必要
- バッチ処理
1ファイルずつ
- Excelでの出力品質
一貫性のないフォーマット
汎用OCRツール
- テーブル構造の保持
複雑なテーブルでは壊れることが多い
- 財務コンテキストの理解
限定的なコンテキスト認識
- 引用のトレーサビリティ
通常利用不可
- バッチ処理
限定的なマルチファイルワークフロー
- Excelでの出力品質
大幅なクリーンアップが必要
Compound
- テーブル構造の保持
財務テーブルレイアウトで信頼性が高い
- 財務コンテキストの理解
財務ドキュメント専用に構築
- 引用のトレーサビリティ
デフォルトでスパンレベルの引用
- バッチ処理
1つのワークスペースで数十のPDFを分析
- Excelでの出力品質
クリーンで数式対応のワークブック
サンプルPDFをアップロードして、数分で結果を確認
財務ワークフロー向けの監査可能な出力
Compoundは、投資メモやIC議論に到達する前にすべての数値を検証する必要があるアナリスト向けに構築されています。
スパンレベルの引用
抽出されたすべての値は、正確なソースページまで遡ることができます。
構造化された型付きセル
日付、パーセンテージ、通貨、数値は、下流作業に適した形式で配置されます。
数式対応のワークブック出力
出力は、独自の仮定、感応度分析、モデル拡張にすぐに使用できます。
迅速な人間による検証
元のPDFを検索することなく、抽出されたテーブルを迅速にレビューおよび検証できます。
よくある質問
Compoundは、スキャンされたドキュメント、ネイティブPDF、財務提出書類(10-K、10-Q)、ピッチデック、データルームファイルなどを処理します。複雑なテーブルレイアウトで業界をリードする精度を実現するため、マルチモーダル処理を使用しています。
はい。Compoundは、適切なセルフォーマット、数値タイプ、数式を備えたExcelファイルを生成します。すぐに監査および拡張できるワークブックを取得でき、値の単純な貼り付けではありません。
1つのワークスペースに数百のファイルをアップロードできます。Compoundの無限コンテキストアーキテクチャにより、AIがすべてのファイルを検索して、必要なデータを見つけて抽出できます。
CompoundはSOC 2 Type II認証を取得しており、保存時および転送中にAES-256暗号化を使用しています。お客様のドキュメントはモデルトレーニングに使用されることはなく、最高レベルのセキュリティを必要とするチーム向けにVPCデプロイメントが利用可能です。
はい。Compoundは各ページのビジュアルレイアウトを読み取るマルチモーダルAIを使用して、ネイティブPDFとスキャンされたPDFの両方を処理します。フォーマットが不均一な低品質のスキャンデータも正確に処理されます。
CompoundはCIM、10-K、10-Q、年次報告書、オファリングメモランダム、賃料ロール、銀行取引明細書、投資家向けプレゼンテーション、および表形式の財務データを含むあらゆるPDFに最適化されています。AIは一般的な財務諸表の構造をそのまま理解します。
Adobe AcrobatやTabulaのような汎用ツールは、財務コンテキストを理解せずにテーブルをフラットなグリッドとして抽出します。Compoundは「売上高」が明細項目であることを理解し、階層的なテーブル構造を保持した上で、ソースへの引用付きの数式対応Excelを出力します。
はい。ワークブックの構成方法——どのタブを使用するか、列ヘッダーは何か、明細項目のグループ化方法——をCompoundに正確に指示できます。テンプレートワークブックをアップロードして、そのレイアウトやフォーマットの規則に合わせるようCompoundに依頼することもできます。
はい。Compoundは複数言語のPDFに対応しており、ドキュメントの言語に関係なく財務データを抽出できます。そのため、クロスボーダーのディールチームや国際的なリサーチにも適しています。